
Meta has taken another step towards creating a universal language translator.
The company has open-sourced an AI model that translates over 200 languages — many of which aren’t supported by existing systems.
The research is part of a Meta initiative launched earlier this year.
Greetings, humanoids
Subscribe to our newsletter now for a weekly recap of our favorite AI stories in your inbox.
“We call this project No Language Left Behind, and the AI modeling techniques we used from NLLB are helping us make high quality translations on Facebook and Instagram for languages spoken by billions of people around the world,” Meta CEO Mark Zuckerberg said in a Facebook post.
NLLB focuses on lower-resource languages, such as Maori or Maltese. Most people in the world speak these languages, but they lack the training data that AI translations typically require.
Meta’s new model was designed to overcome this challenge.
To do this, the researchers first interviewed speakers of underserved languages to understand their needs. They then developed a novel data mining technique that generates training sentences for low-resource languages.
Next, they trained their model on a mix of the mined data and human-translated data.
The result is NLLB-200 — a massive multilingual translation system for 202 languages.
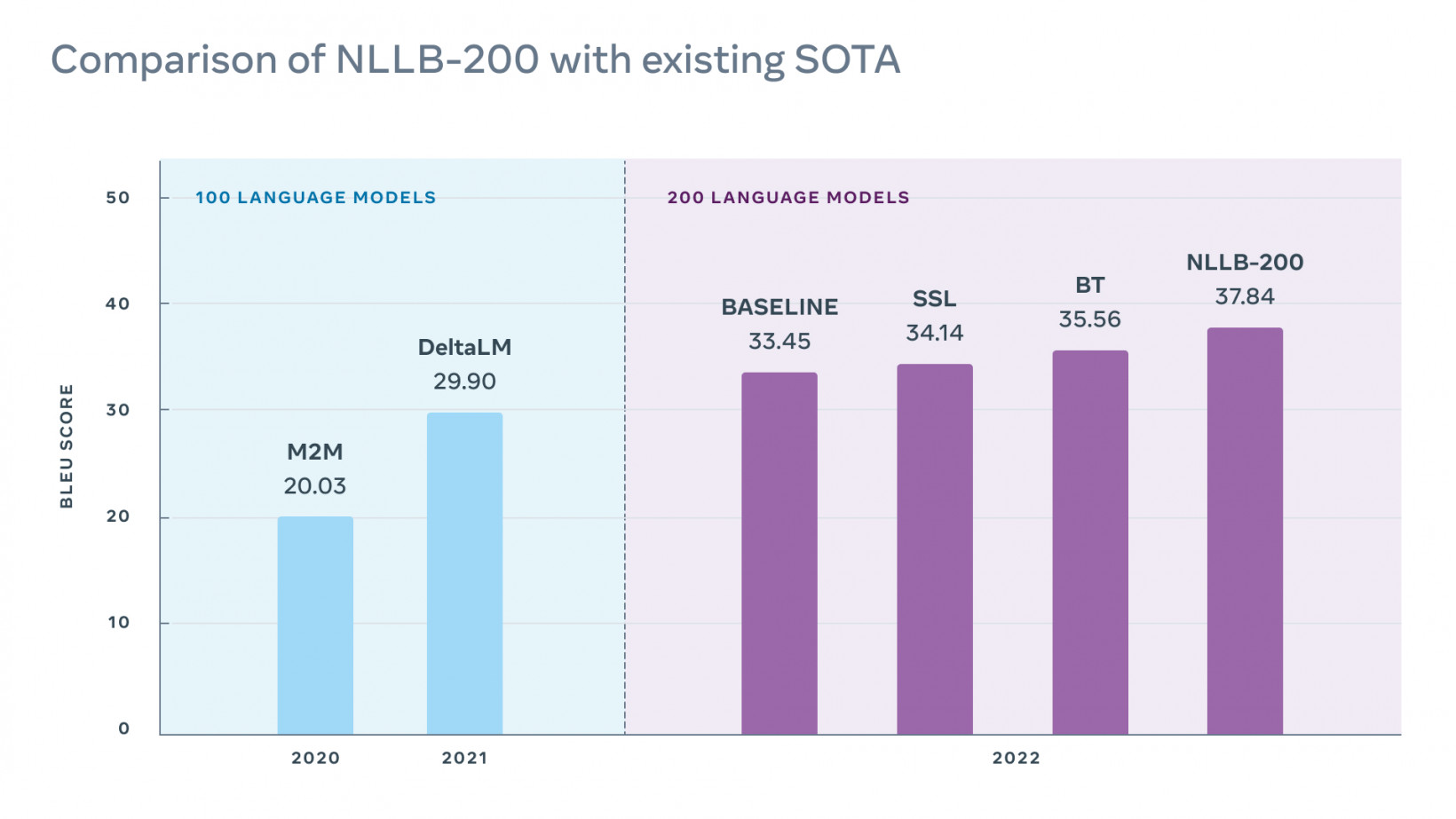
The team assessed the model’s performance on the FLORES-101 dataset, which evaluates translations of low-resource languages.
“Despite doubling the number of languages, our final model performs 40% better than the previous state of the art on Flores-101,” the study authors wrote.
The techniques have already improved machine translations on Facebook, Instagram, and Wikipedia. Meta has also open-sourced all their benchmarks, data scripts, and models to support further research.
This, of course, could also benefit Meta.
Open-sourced for all
Zuckerberg’s relentless drive for growth has recently run into obstacles. In February, Facebook lost daily users for the first time in its 18-year history.
If Meta can improve the quality of its translations, that can make its apps attractive to a broader user base.
Inevitably, the company anticipates the research playing a big role in the metaverse — where concerns about inclusion are growing. But it can also benefit the business’ existing apps.
Translation issues have long caused problems for Meta. In 2017, Israeli police arrested a Palestinian after Facebook translated a post saying “good morning” as “attack them.”
The company has also struggled to monitor misinformation and hate speech in lesser-resourced languages.
The new research could mitigate these risks and improve user experiences. To Meta’s credit, the company has also given rivals a chance to benefit from the work. Open-sourcing the models will also hopefully support speakers of languages that are underserved or under threat.
In this case, what benefits Meta could also benefit humanity. It also brings the fantasy of a universal translator closer to reality.

{kind=link}